TrainingPhoneBuddy
Training open phone-use models with real-app RL and PhoneWorld-style mock-app training, showing that realism and scalable verified interaction are complementary.
PhoneBuddy studies how to train open phone-use agents with both real-app execution and scalable mock-app environments. The core result is simple: real-app RL provides realism, while PhoneWorld-style mock-app training adds resettable and automatically verified interaction signal.
PhoneBuddy sits in a broader phone-agent stack: environments for scalable interaction, training recipes for open models, runtime harnesses for real execution, and deployment boundaries for privacy and safety.
Training open phone-use models with real-app RL and PhoneWorld-style mock-app training, showing that realism and scalable verified interaction are complementary.
A scalable pipeline that turns real GUI trajectories and screenshots into controllable phone-use environments, executable tasks, verifiers, and training rollouts.
A mixed-action phone-agent harness and benchmark that routes across CLI, GUI, and MCP tools with trace-backed verification.
A verifiable benchmark for privacy behavior in mobile agents, auditing permissioned access, minimal disclosure, and user-controlled memory.
Safety evaluation for phone-use agents, separating true safety behavior from simple incapability and checking risky mobile side effects.
PhoneBuddy-4B-Real+Mock improves the same open-model line across real-phone and AndroidWorld settings. The visual summary below separates main capability comparison from the cross-app limitation.
The radar compares PhoneBuddy-4B-Real+Mock against GPT-5.4, Gemini 3.1 Pro, and Seed 2.0 across the same five axes. PhoneBuddy is strongest on AndroidWorld and single-app tasks, while cross-app transfer remains the visible weak axis.
 GPT-5.4
GPT-5.4 Seed 2.0
Seed 2.0 Gemini
GeminiMixed real+mock training is the strongest PhoneBuddy checkpoint and closes much of the gap to larger proprietary agents.
GPT-5.4Seed 2.0GeminiAndroidWorld shows a clean progression from SFT to real-app RL to mixed real+mock RL.
Seed 2.0GPT-5.4GeminiGPT and Gemini are shown separately; both score 50.0 on this slice.
GPT-5.4GeminiSeed 2.0Mock-app practice helps recover mini-app reliability after real-only training.
| Model | Single-App | Cross-App | WeChat Mini-App | AndroidWorld | Avg. |
|---|---|---|---|---|---|
| PhoneBuddy-4B-SFT | 34.0 | 22.0 | 54.0 | 60.3 | 42.6 |
| PhoneBuddy-4B-Real | 54.0 | 20.0 | 48.0 | 77.2 | 49.8 |
| PhoneBuddy-4B-Real+Mock | 62.0 | 18.0 | 56.0 | 83.2 | 54.8 |
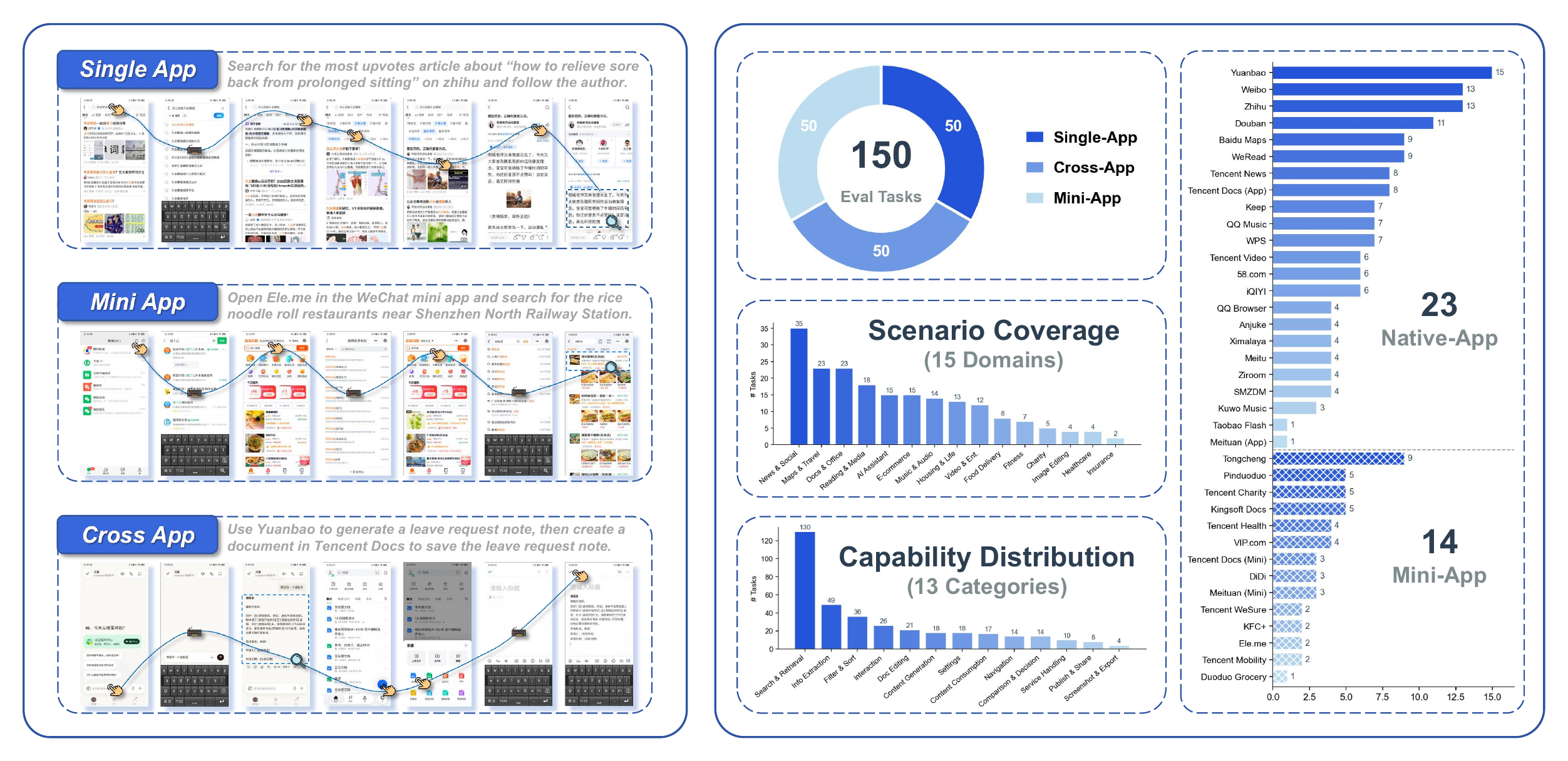
Evaluation covers real-phone Single-App, Cross-App, WeChat Mini-App tasks, plus AndroidWorld.
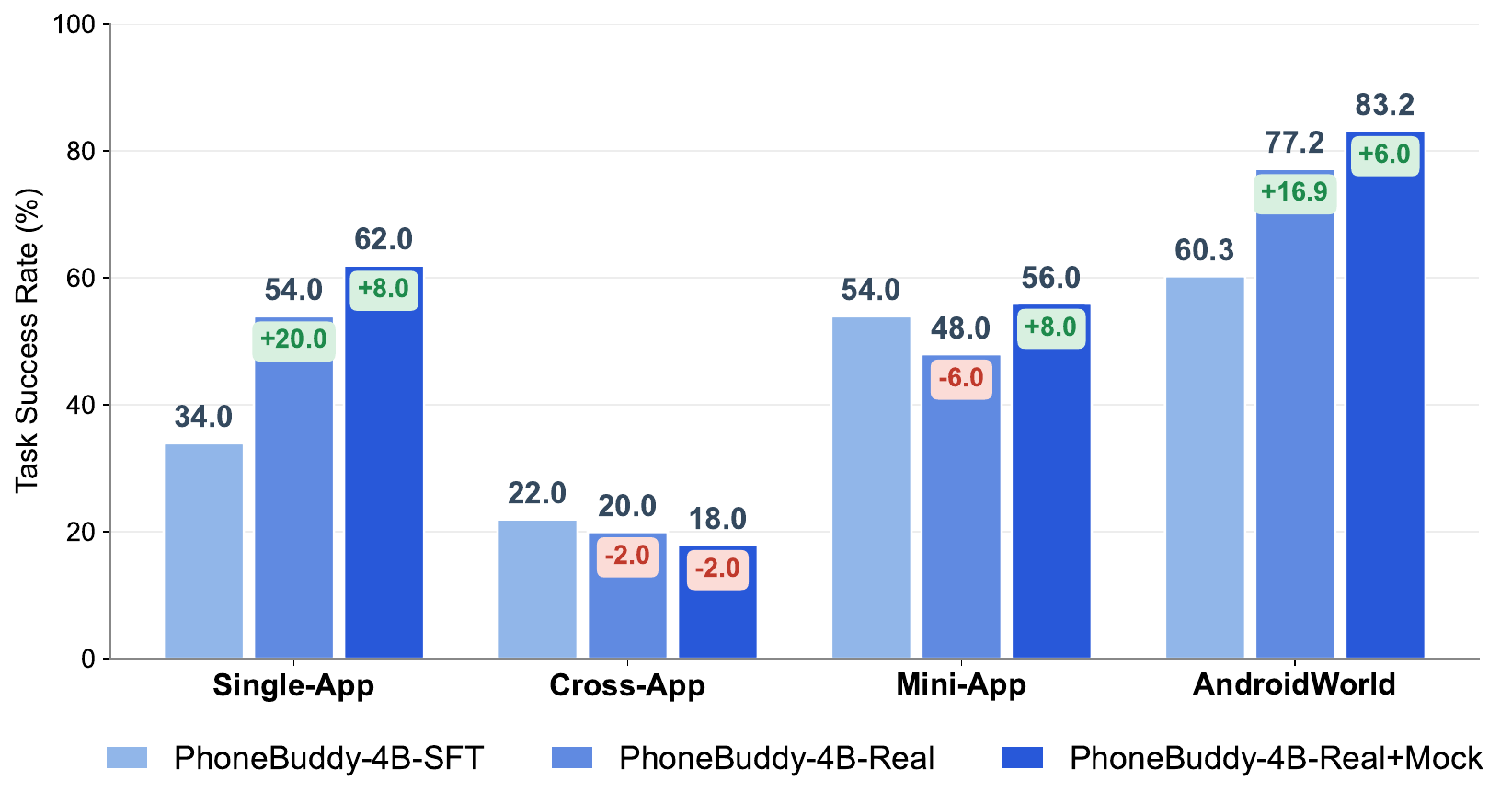
Delta view of real-app RL over SFT and mixed real+mock RL over real-app RL.
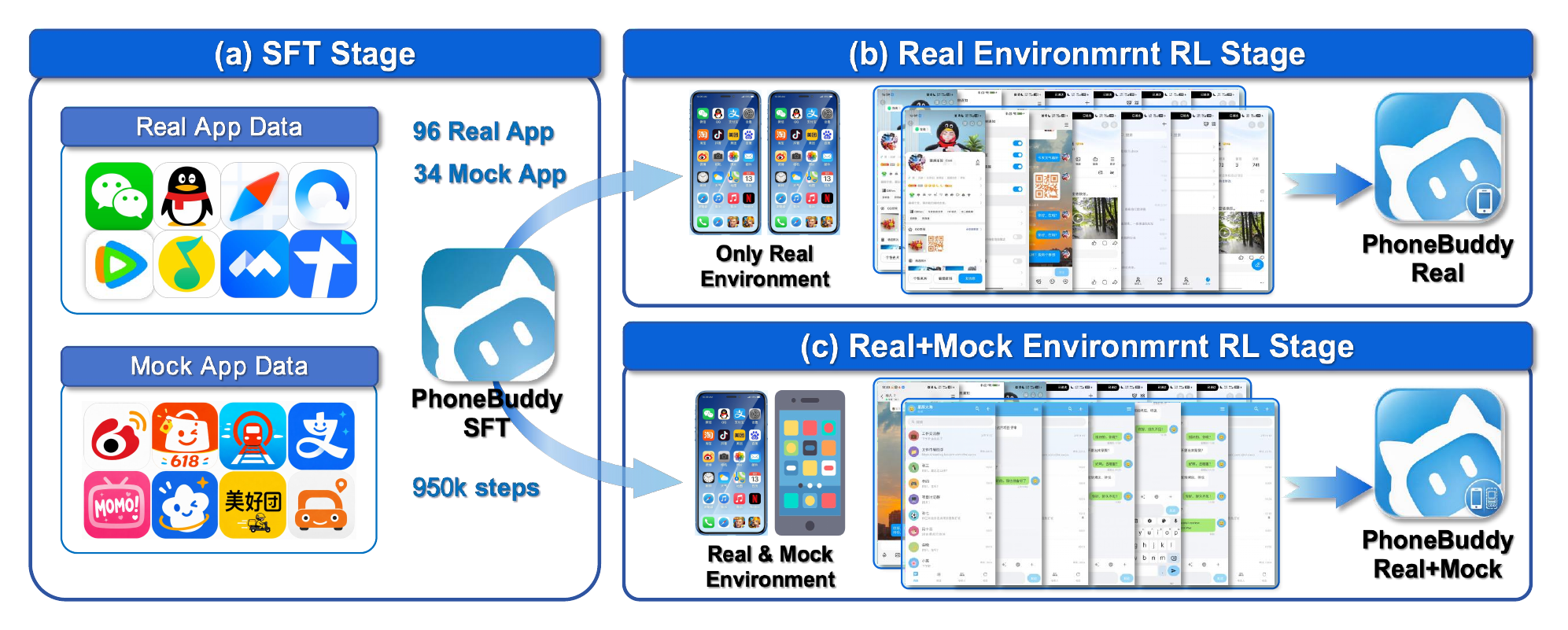
PhoneBuddy compares a shared SFT checkpoint, a real-app RL checkpoint, and a mixed real+mock RL checkpoint under the same backbone, action interface, and evaluation protocol.
Real devices and authentic apps expose account state, app logic, timing variation, permission flows, and real side effects.
Runnable mock apps reconstructed from real GUI usage structure provide resettable training tasks and automatic verification.
The final branch keeps real execution in the loop while adding scalable mock-app interaction for broader and cheaper training signal.
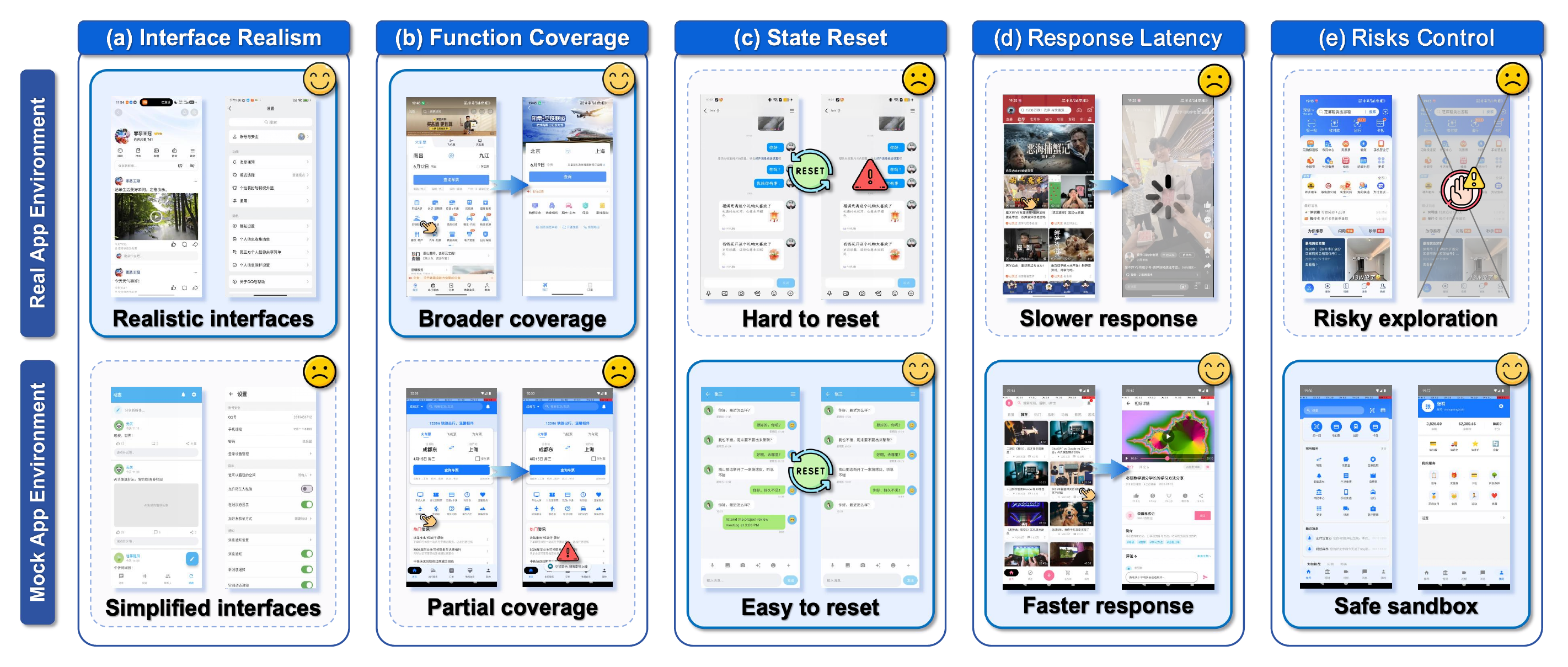
The real-app environment anchors training to authentic behavior; the mock-app environment contributes scale, reset, and automatic checking.
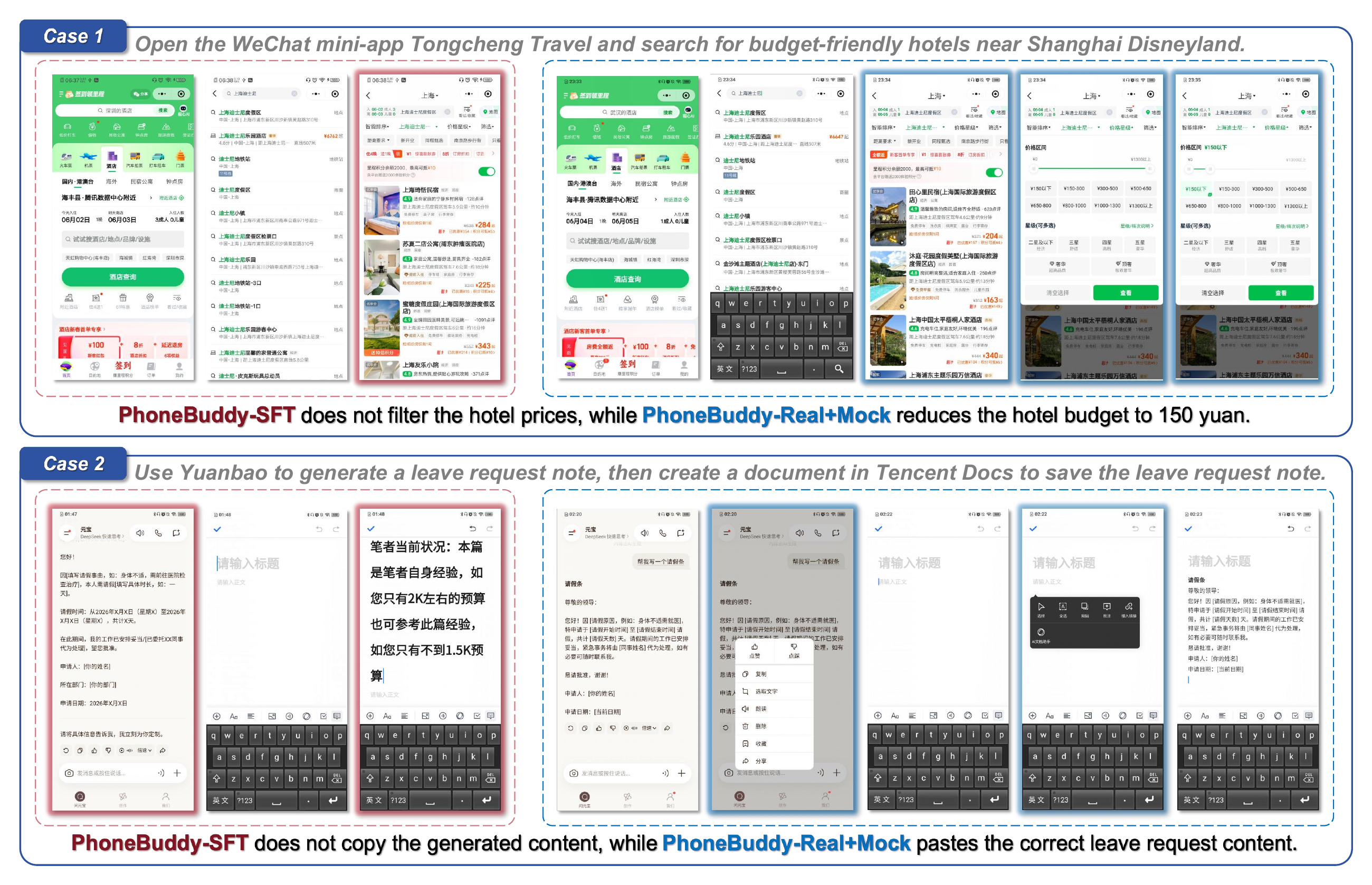
Representative successful trajectories show structured workflows where mock-app training improves execution reliability.
PhoneWorld-style mock tasks currently emphasize single-app interaction rather than cross-app handoff. The ablation therefore compares only PhoneBuddy checkpoints and shows that mock-domain coverage matters for cross-app workflows.